Man stelle sich vor, es gäbe keine Links im WWW. Oder noch besser: Wir packen linkfreie HTML-Dokumente in ein Zip-Archiv und bieten dieses zum Download an. Klingt total bescheuert? Ist es auch. Denn mit einem “World Wide Web” hat das dann nichts mehr zu tun.
Aber wie gehen wir eigentlich mit Daten um? Die Einsicht, dass Rohdaten in maschinenlesbarer Form veröffentlicht werden müssen, breitet sich so langsam aus. Doch reicht das wirklich aus? Ist es in Ordnung CSV- oder XML-Dateien in ZIP-Archive zu packen und zum Download anzubieten, wie es zum Beispiel data.gov tut? Es ist ein Segen im Vergleich zum Vorgehen deutscher Behörden, die Daten in PDF-Dokumenten oder Flash-Anwendungen verstecken, oder sie ganz vom Internet fern halten. Aber es ist nicht so wie es sein sollte. Es ist genauso irrsinnig wie der oben beschriebene Umgang mit HTML-Dokumenten.
Wir brauchen keine Website von der man Daten herunterladen kann. Wir benötigen ein Web aus Daten. Die Daten selbst müssen zu einem weltweiten, grenzenlosen Netz werden. Niemand geringeres als der Erfinder des WWW, Tim Berners-Lee, fordert eben dies schon seit 2006. Er beschreibt 4 Grundprinzipien für “Linked Data”:
- Use URIs as names for things
- Use HTTP URIs so that people can look up those names
- When someone looks up a URI, provide useful information, using the standards (RDF, SPARQL)
- Include links to other URIs. so that they can discover more things
Die Regeln sind im Grunde genommen sehr einfach. Und doch verlangen sie ein grundlegendes Umdenken im Umgang mit Daten und dem Web insgesamt. Die erste Regel verlangt, dass wir URIs verwenden um Dinge zu benennen. Wir identifzieren bereits Webseiten über URIs – genauer: URLs – und auch die besagten ZIP-Pakete werden so identifiziert. Hier muss der erste Umdenkprozess ansetzen: Wir identifzieren nicht mehr nur Webseiten und Dateien über URIs, sondern alle möglichen Dinge. Der Begriff “Ding” beschränkt sich dabei nicht auf konkrete, physische Objekte sondern umfasst prinzipiell alles Exisitente oder Denkbare, auch Personen, Organisationen, abstrakte Konzepte, Themengebiete, Termine und ähnliches fallen darunter.
Die zweite Regel hat einen eher technischen Hintergrund. HTTP-URIs haben schlicht den Vorteil, dass sie über das Domain Name System auflösbar sind.1 Dies ist nötig um die dritte Regel zu erfüllen: Über die URI müssen nützliche Informationen über das identifzierte “Ding” abrufbar sein. Dass nur strukturierte Rohdaten in offenen Formaten wirklich nützlich sind, weiß jeder der die Open Data Principles verinnerlicht hat. Doch Berners-Lee fordert ausdrücklich Standards wie RDF und SPARQL.
Nie gehört? Womöglich, denn die meisten maschinenlesbaren Daten die im Web zu finden sind, liegen in Form von XML oder CSV vor. Ich werde an dieser Stelle zumindest kurz auf RDF eingehen. Wo liegt das Problem bei CSV? Das Problem sollte spätestens klar werden, wenn man einen Blick auf diese Datei wirft und versucht folgende Fragen zu beantworten:
- Welche Daten sind in der Datei enthalten? Worum geht es?
- Was bedeutet ein einzelner Datensatz / eine Zeile dieser Datei?
- Was bedeutet der Wert in Spalte 3 (und den anderen Spalten)?
CSV-Dateien sind nur verwertbar, wenn die Bedeutung der Daten zwischen den Kommunikationspartnern (d.h. dem der die Daten bereitstellt und demjenigen der sie weiter verarbeitet) abgestimmt ist. Außerdem muss die Bedeutung in die Anwendungen, die die Daten nutzen wollen implementiert werden. Unterschiedliche Anwendungen und sogar unterschiedliche Versionen der gleichen Anwendung könnten die Daten völlig unterschiedlich interpretieren, da die Bedeutung der Daten aus ihnen selbst nicht hervorgeht.
Anders bei RDF: Dieses Datenmodell speichert Informationen in Form von sogenannten “Tripeln”, bestehend aus Subjekt, Prädikat und Objekt. Subjekt ist die Ressource (das “Ding”), die beschrieben wird, Prädikat ist die Aussage die wir über diese Ressource treffen und Objekt ist der Wert oder Gegenstand dieser Aussage. Der Satz “Koblenz liegt am Rhein” ist im Grunde genommen ein RDF-Tripel bei dem “Koblenz” das Subjekt, “liegt am” das Prädikat und “Rhein” das Objekt ist. RDF ist lediglich ein Modell, und als solches nicht an eine spezielle Syntax gebunden. Die wichtigsten Notationsweisen stellt dieser Artikel vor.
RDF ordnet Daten in den Kontext ihrer Bedeutung ein. Während in einer CSV-Datei vermutlich in irgendeiner Spalte einfach nur das Wort “Rhein” stehen würde, enthält das RDF-Modell die komplette Aussage “Koblenz liegt am Rhein”. Ein Web aus Daten entsteht jedoch erst durch Beachtung der vierten Regel: Wir verlinken unsere Daten und erschließen so neue Zusammenhänge! Für unser Beispiel bedeutet dies, dass “Koblenz” und “Rhein” nicht einfach Datenwerte sind, sondern Ressourcen die über eine URI identifiziert werden, bei deren Abruf weitere nützliche Informationen geladen werden (Regel 3!). Zum Beispiel könnten wir durch Abruf der Ressource “Rhein” Informationen über dessen Länge finden, oder welche Städte noch an diesem Fluss liegen (Bzw. die Information, dass es sich dabei überhaupt um einen Fluss handelt!). Das enorme Potential, das die Verlinkung von Daten bietet, kann durch den folgenden RDF-Graphen bestenfalls angedeutet werden:
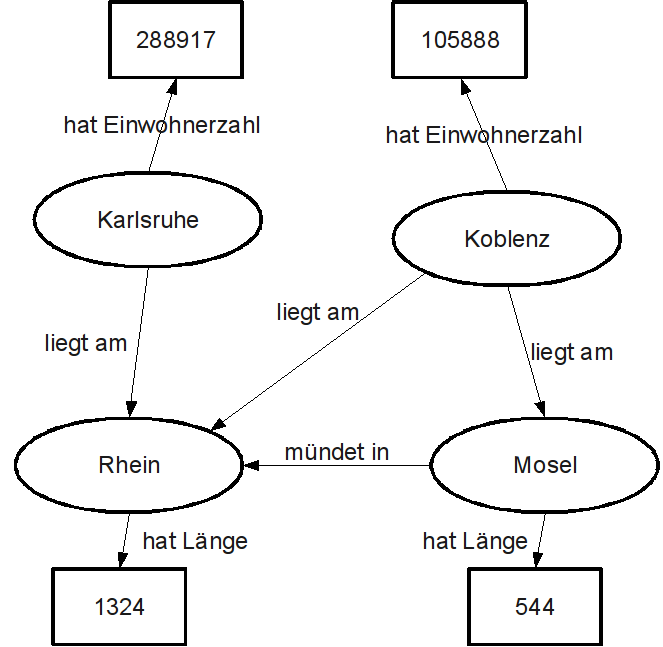
Ziel ist es, ein weltweites Netz aus Daten zu schaffen, in dem Informationsbestände nicht mehr voneinander abgeschottet in Datenbanken und ZIP-Archiven vermotten, sondern einen globalen Informationsraum bilden, der uns völlig neue und unerwartete Informationszusammenhänge offenbaren wird.
Weitere Informationen zu Linked Data gibt es hier in diesem Blog. Eine detailliertere Betrachtung bietet meine Studienarbeit “Chancen und Techniken von Linked Data”. Ansonsten ist linkeddata.org ein guter Ausgangspunkt für eigene Recherchen.
1 Es gibt zum Beispiel Spezial-URIs für ISBN, die auf den ersten Blick hervorragend scheinen um Bücher zu identifzieren. Da diese aber nicht auflösbar (vereinfacht gesagt: über den Browser abrufbar) sind, sollte man sie für den Aufbau eines Webs aus Daten nicht verwenden, sondern sich auf die etablierten HTTP-URIs beschränken.
Ein Gedanke zu „Warum wir Daten verlinken müssen“