Was ist Solid? In 30 unterhaltsamen und leicht verdaulichen Comics hat Patrick Hochstenbach dies im „Solvember“ erklärt – jeden Novembertag gab es ein neues Bildchen zum Thema Solid.
Angefangen bei den Grundlagen zeigen die Protagonist*innen Alice und Bob unter anderem wie Zugriffskontrolle mittels WebACL und Linked Data Notifications funktionieren und was das für die beiden in der Praxis bedeutet.
Schaut es euch an! Alle Abenteuer von Alice und Bob findet ihr zum Durchstöbern auf seinem Solid Pod.
Bei Diensten wie Twitter, vertraue ich meine Inhalte und Daten einem zentralen Anbieter an. Das kann zum Problem werden, da ich von diesem Anbieter abhängig werde und die Kontrolle verliere, ob und wie lange meine Daten für mich und andere verfügbar sind. Ich möchte jedoch Datensouveränität, also meine Daten langfristig für eigene Zwecke nutzen können. Ich habe deshalb alle meine Tweets in einen Solid Pod exportiert.
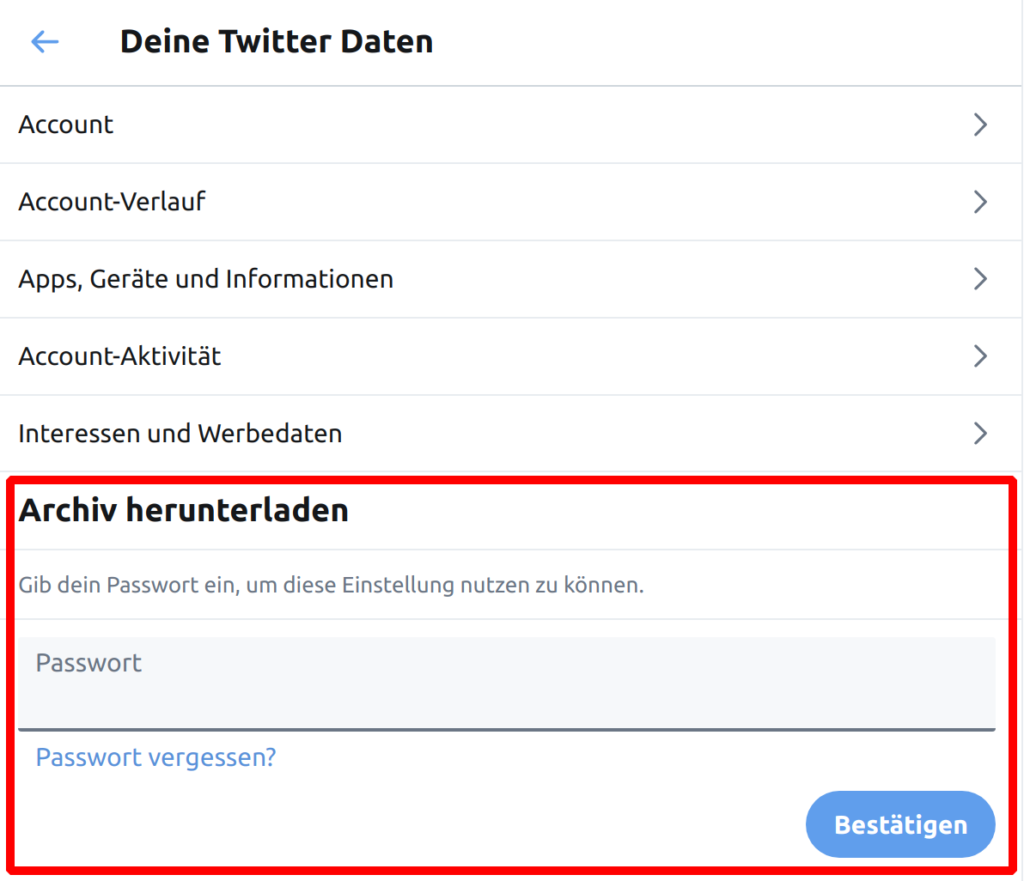
Dank der DSGVO sind Twitter und Co. inzwischen verpflichtet, persönliche Daten auf Anfrage maschinenlesbar heraus zu geben. Bei Twitter findest du die Option in den Account Einstellungen unter „Deine Twitter Daten“:
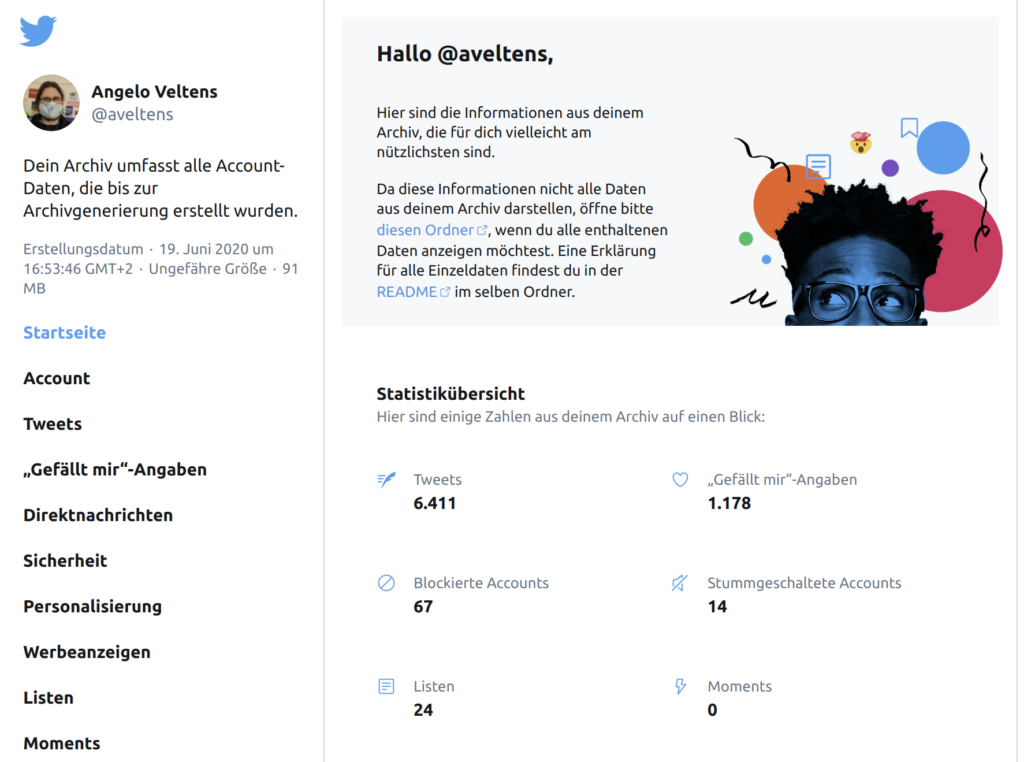
Sobald Twitter dir das Archiv bereit gestellt hat, kannst du dessen kompletten Inhalt auf einen Solid Pod hochladen. Neben strukturierten JSON-Daten enthält es auch eine hübsche HTML Variante, die du unter der entsprechenden Pod-URL abrufen kannst:
Nun hast du ein persönliches Online-Archiv all deiner Twitter-Aktivitäten, das dir niemand mehr wegnehmen kann. Die Zugriffsrechte des Ordners solltest du auf jeden Fall beschränken, da das Archiv auch private Daten, wie zum Beispiel Direktnachrichten enthält.
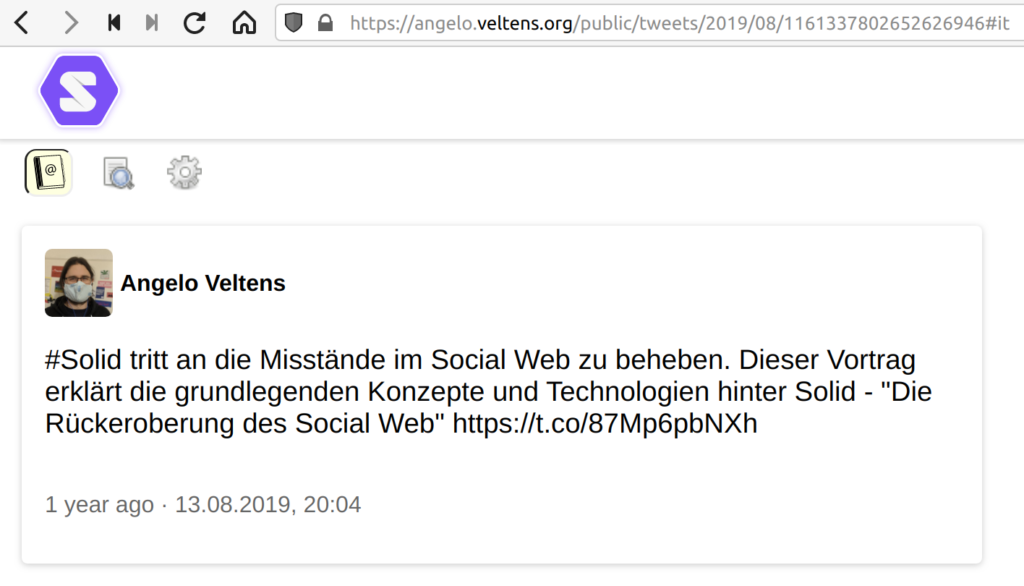
Die HTML-Seite ist ganz nett, die Stärke von Solid liegt aber in der Verlinkung von Daten, um diese in anderen Kontexten nutzbar zu machen. Ich möchte, dass andere auf die Tweets verweisen können, um mit ihnen zu interagieren. Ich habe daher die öffentlichen Tweets auch als Linked Data in meinem Pod verfügbar gemacht.
Im Original-Archiv liegen alle Tweets maschinenlesbar in der Datei data/tweet.js vor. Mit einem kleinen NodeJS-Skript habe ich diese zu Linked Data konvertiert. Zunächst iteriert das Skript durch die Liste der Tweets und legt für jeden Tweet eine Ressource in einem rdflib Store an:
Ich habe mich für das Activity-Streams-Vokabular entschieden, da dieses bereits erfolgreich im Fediverse (z.B. Mastodon) verwendet wird und ich möglichst kompatibel werden möchte. Nachdem alle tweets zum Typ as:Note konvertiert wurden exportiere ich jede Ressource in eine eigene Turtle (.ttl) Datei. Dadurch können bei Bedarf feingranulare Zugriffsrechte gesetzt werden:
Wie finde ich interessante Daten in Solid Pods? Solid arbeitet nach dem Prinzip „Follow your nose“. Sowohl Menschen, als auch Maschinen und Apps können damit, ausgehend vom Social-Web-Profil, weitere interessante Daten finden.
Mit diesem Prinzip, kannst du zum Beispiel die Folien meiner Vorträge in meinem Solid Pod entdecken. Legen wir los!
Ausgangspunkt ist mein Profil unter https://angelo.veltens.org/profile/card. Es verlinkt meine WebID mit einer Vielzahl weiterer Informationen. Wenn du den Link anklickst, öffnet sich der „Solid Data Browser“. Nicht erschrecken: er ist noch sehr hässlich, aber dennoch äußerst nützlich, um „Follow your nose“ zu verdeutlichen.
Relativ weit oben findest du meinen Namen „Angelo Veltens“ gefolgt von „performer In“ und einer Auflistung von „it“. Es handelt sich dabei um Daten-Tripel, die eine Beziehung zwischen mir und weiteren Dingen herstellen.
Alle Bestandteile dieser Tripel sind Links, die wir anklicken können, um zu verstehen was genau dahinter steckt. Klicke mit der mittleren Maustaste auf „performer In“, um den Link in einem neuen Tab zu öffnen. Du befindest dich nun auf schema.org und erfährst:
Event that this person is a performer or participant in.
Beschreibung der Beziehung „performerIn“ bei schema.org.
Wir wissen nun also, dass „perfomer In“ auf Veranstaltungen verweist, auf denen ich aufgetreten bin. Folgen wir dieser Spur weiter! Zurück auf der Profilseite klickst du auf einen der „it“-Links, um Informationen zur jeweiligen Veranstaltung abzurufen. Dort werden wir womöglich auf Vortragsfolien stoßen.
Im Data Browser öffnen sich nun Informationen zur ausgewählten Veranstaltung. Ab jetzt geht es in einer Baumstruktur weiter. Frag mich nicht warum – ich sagte bereits, das User Interface ist murks 🤷♂️. Bitte versuche es für den Moment zu akzeptieren und das dahinterliegende Prinzip zu verstehen.
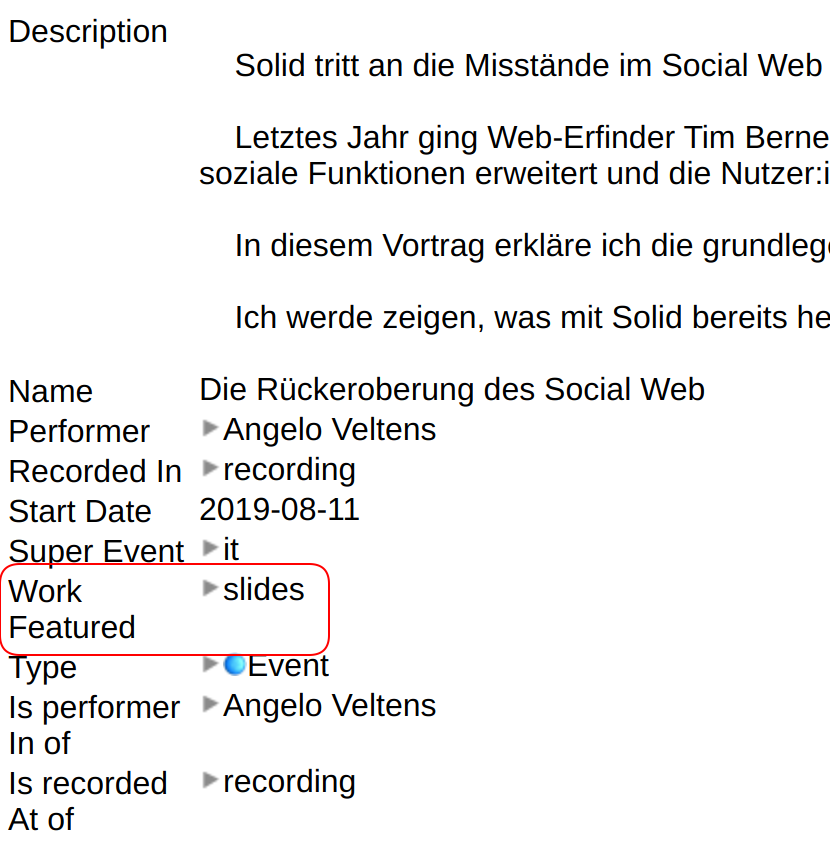
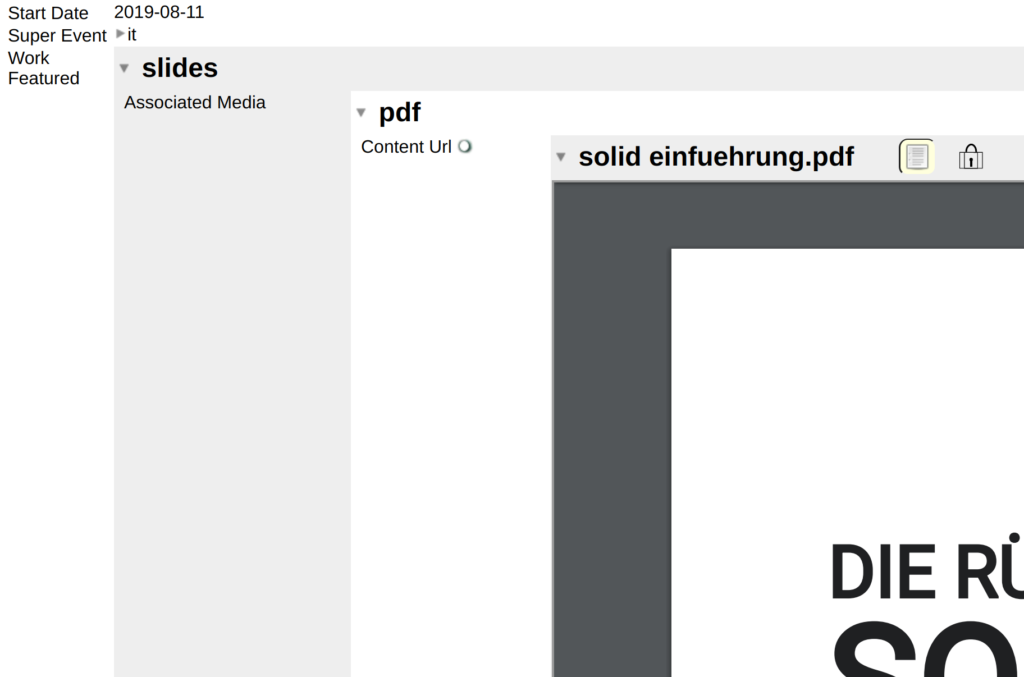
In den Veranstaltungsdaten findest du neben Name und Beschreibung auch einen Punkt „Work Featured“. Klicke auf das kleine Dreieck vor „slides“, um weitere Daten auszuklappen. Der Type „Presentation Digital Document“ lässt erahnen, dass wir die Folien gefunden haben.
Daten eines Events in einer aufklappbaren Baumstruktur. „Work featured“ führt weiter zu den Vortragsfolien.
Um die Folien einzusehen, müssen wir aber noch die konkreten Dateien finden. Davon kann es mehrere geben. Unter „Associated Media“ kannst du einen weiteren Abschnitt „web“ und/oder „pdf“ aufklappen und kommst dort zu konkreten Ausprägungen der Folien (PDF oder HTML). Wenn du nun noch die „Content Url“ aufklappst kannst du die Folien betrachten. (Alternativ kannst du den Wert von „Content Url“ per drag-and-drop in die Browserleiste ziehen – erneut 🤷♂️)
Einige Ebenen tiefer finden sich die konkreten Dateien der Vortragsfolien. In diesem Bild als PDF-Dokument.
Wozu der ganze Aufriss?
Zugegeben, das war jetzt nicht nur wegen des Data-Browser-UIs eine schlechte User Experience. Darum geht es hier aber auch gar nicht.
Ein wichtiger Aspekt von Solid ist die grundsätzliche Auffindbarkeit von Daten, ausgehend vom Profil einer Benutzer:in, allein durch das Folgen von Links. In der Praxis wird das, was wir hier mühsam von Hand durchgeführt haben, durch Apps automatisiert.
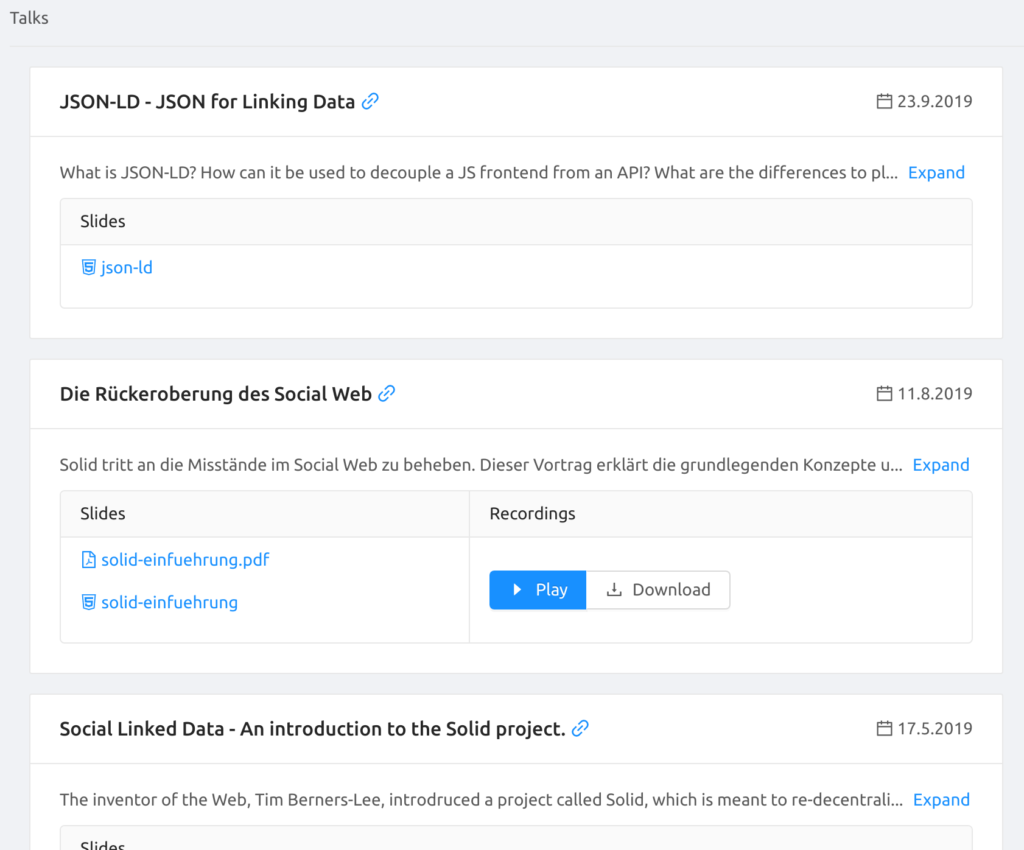
Wirf einen Blick in den Abschnitt „Talks“ meiner Website. Die Seite macht genau das, was wir gerade getan haben, nur viel schneller und automatisch. Dadurch ist die Seite in der Lage alle Infos, Folien und Videoaufzeichnungen meiner Talks gebündelt und gut zugänglich darzustellen.
Durch die Trennung von Apps und Daten, sind auch andere Webseiten und Anwendungen in der Lage, diese Informationen zu verwerten.
Das Follow-your-nose-Prinzip lässt sich automatisieren. Apps können die Daten dann auch „in hübsch“ anzeigen.
Ich habe gestern Version 0.5 von wp-linked-data veröffentlicht. Mit diesem WordPress Plugin könnt ihre euer Blog und die Blogartikel als Linked Data verfügbar machen und somit auch mit eurem Solid Profil verknüpfen.
In meinem Solid Profil habe ich dazu folgendes Tripel hinterlegt:
:me <foaf:weblog> <https://datenwissen.de#it>.
Mit folgendem LDflex Ausdruck könnt ihr z.B. die letzten Blogartikel von datenwissen.de ermitteln:
Die Idee eines Social Webs, losgelöst von zentralen Plattformen, rückt mit dem Solid-Projekt in greifbare Nähe.
Was ist Solid? – Solid steht für Social Linked Data. Das Projekt basiert auf Linked Data und vereint zahlreiche W3C-Standards aus diesem Umfeld, um das World Wide Web als Plattform für soziale Interaktionen zu nutzen.
Damit unterscheidet es sich wesentlich von verteilten sozialen Netzwerken wie Diaspora, Mastodon und Co., die im Grunde nur verteilte Daten-Silos sind. Mit Solid kann jede Website, jede Webanwendung, Teil des neuen Social Webs werden.
Eine Grundidee von Solid besteht in der Trennung von Anwendungen und Datenspeichern. Die Daten können an beliebigen Orten im Web gespeichert werden. Als Benutzer:in habe ich freie Wahl, wo ich meine Daten speichern will und wem ich Zugriff darauf gebe. Ebenso kann ich wählen, mit welchen Anwendungen ich die Daten verwalten möchte.
Dieses Prinzip möchte ich an einem konkreten Beispiel verdeutlichen:
Unter https://angelo.veltens.org/ läuft ein Solid-kompatibler Server. Aus dem dokumentenbasierten Web kennen wir Server wie nginx oder Apache httpd. Ein Solid-Server ist diesen sehr ähnlich, stellt aber darüber hinaus Funktionen für das Social Web bereit. Es ist auch denkbar, dass bestehende Webserver um Solid-Funktionen erweitert werden.
Der Server stellt mir eine Identität in Form einer WebID zur Verfügung und dient als „Personal Online Datastore“ (POD) zum Speichern von Daten. Unter meiner WebID https://angelo.veltens.org/profile/card#me sind einige Basis-Informationen zu meiner Person abrufbar. Alle weiteren Daten, die ich im POD, oder an anderen Orten im Web gespeichert habe, sind von dort aus verlinkt. Unter https://angelo.veltens.org/public/bookmarks liegen zum Beispiel einige meiner öffentlichen „Social Bookmarks“.
Der Solid-Server stellt auch ein rudimentäres Web-Interface zum Anzeigen und Bearbeiten der Daten bereit. Das spannende an Solid ist jedoch, dass ich beliebige Solid-Apps im Web verwenden kann. Zum Anlegen von Bookmarks zum Beispiel markbook.org. Ich habe markbook.org dazu schreibenden Zugriff auf https://angelo.veltens.org/public/bookmarks erteilt. Wenn ich mich mit meiner WebID einlogge, kann die App meine Lesezeichen verwalten.
Das gute an Solid ist, dass diese Lesezeichen eben nicht auf dem Server von markbook.org gespeichert werden, sondern in meinem POD. Wenn ich mit der Anwendung nicht mehr zufrieden bin, kann ich zu einer anderen Bookmark-App wechseln und die Daten einfach dort verwalten. Ebenso kann ich unterschiedliche Daten in unterschiedlichen PODs speichern und so im Web verteilen. Ich muss dabei auch nicht unbedingt einen eigenen Server betreiben, sondern kann auf Provider, wie z.B. inrupt.net zurück greifen. Dank Linked Data können alle Daten untereinander verknüpft und beliebigen Web-Apps zugänglich gemacht werden.
Dies geht soweit, dass jede Nutzer:in volle Kontrolle über die eigenen Daten hat. Während Alice einen Beitrag unter https://alice.example/articles/hello-world veröffentlicht, schreibt Bob einen Kommentar dazu unter https://bob.example/comments/my-two-cents und Trudy äußert ihre Zustimmung zu Bobs kommentar mit einem „Like“ unter https://trudy.example/likes/2019/02#123. Durch die Verlinkung der Daten kann alles aggregiert direkt beim Artikel angezeigt werden, liegt in Wahrheit jedoch in den PODs der jeweiligen User.
Dies ist soweit die Grundidee hinter Solid, ohne zu sehr auf die technischen Details einzugehen. Über einzelne davon werden sicher noch Blogposts folgen.
Wenn ich eurer Interesse für Solid geweckt habe, hier einige Follow-Up-Resourcen:
In den vergangenen Jahren hatte ich wenig Zeit mich mit Linked Data zu befassen, obwohl mich das Thema nach wie vor interessiert. Inzwischen habe ich mich der Sache aber wieder angenommen und möchte dieses Blog reaktivieren.
Seit 2013 hat sich viel getan. Ein Auszug:
Mit JSON-LD ist ein praxisorientiertes Serialisierungsformat entstanden, mit dem Entwickler:innen schnell vertraut werden.
Auch speziell in den letzten Wochen und Monaten passiert wieder mehr in diesen Bereichen. Die W3C JSON-LD Working Group hat die Arbeit an JSON-LD übernommen. Die Hydra Community Group hat sich neu formiert und arbeitet verstärkt an der Erweiterung der Spezifikation und konkreten Beispielen. Solid vereint eine wachsende Community von Leuten aus unterschiedlichen Bereichen. Im Chat und im Forum ist immer was los.
Ich selbst habe im codecentric-Blog Artikel über JSON-LD geschrieben, arbeite derzeit an Hydra-APIs und experimentiere mit Solid. Mehr erfahrt ihr demnächst hier im Blog.
Ich bin ein bisschen spät dran, aber die Folien meines Vortrags ‚Let’s tear down these walls – „Mit Links” die Mauern Sozialer Netzwerke überwinden.‘ sind nun endlich auf github verfügbar. Hier ist auch die Aufzeichnung des Vortrags:
In Ausgabe 02/2013 der Zeitschrift java aktuell wurde ein Praxisartikel von mir zum Thema Linked Data veröffentlicht:
Ein Artikel in der letzten Ausgabe hat in die Grundlagen von Linked Data eingeführt und gezeigt, wie daraus ein Web aus Daten entstehen kann. Linked Data ist jedoch keine bloße Theorie: Mit wenigen Zeilen Code kann eine Anwendung Teil dieses Daten-Webs werden. Der Beitrag zeigt, wie man Linked Data veröffentlichen und in seinen Anwendungen verwerten kann.
Im Artikel wird ein Hotel-Service beschrieben, der Hotel-Informationen als Linked Data verfügbar macht. Eine weitere Anwendung konsumiert diese Daten um die Bewertung der Hotels zu ermöglichen. Der beschriebene Hotel-Service ist unter http://hotels.datenwissen.de/ online. Die Hotel-Bewertung ist über http://hotel-rating.datenwissen.de/ möglich. Beide Anwendungen sind Open Source und auf github verfügbar (Hotel-Service, Bewertungsplattform).
Mein WordPress-Plugin zur Veröffentlichung von Bloginhalten als Linked Data, kurz wp-linked-data, ist nun auch über das WordPress-Plugin-Repository verfügbar. Die Installation ist mit wenigen Klicks erledigt. Wie die meisten anderen Plugins könnt ihr es nun über eueren WordPress-Administrationsbereich finden und installieren. Sucht einfach nach „wp-linked-data“ oder „Linked Data“.